Qu’est-ce qu’une base de données ?
Le nombre d’informations disponibles et les moyen de les diffuser sont en constante progression. La croissance du Web a encore accru ce développement en fournissant l’accès à des bases de données gigantesques et très diverses par l’intermédiaire d’une interface commune (Amazon, Google, Facebook, ...).
Notion de base de données
Tout le monde a une idée naturelle de ce que peut être une base de donnée, nous stockons, sur nos disques durs, non seulement des fichiers musicaux, mais aussi des informations relatives à ces derniers : noms des artistes, des albums, dates d’enregistrements, noms et numéros des morceaux, parfois noms des musiciens, ...
On remarque qu’une caractéristique des données contenues dans une base de données est qu’elles doivent posséder un lien entre elles. En effet, des données choisies au hasard ne peuvent clairement pas constituer une base de données. Une base de données est donc une représentation partielle et (très) simplifiée du monde réel, obtenue par un processus de modélisation.
La définition d’une base de données n’indique pas comment sont stockées les informations, une organisation consistant en l’utilisation de fichiers pourrait tout à fait convenir. Cependant, bien que simple à mettre en œuvre, cette solution pose de nombreux problèmes :
- Lourdeur d’accès aux données
-
En pratique, pour chaque accès aux données (lecture ou écriture), il faut écrire un programme.
- Manque de sécurité
-
Si tout programmeur peut accéder aux données, il est impossible d’assurer leur intégrité.
- Pas de contrôle de concurrence
-
Si plusieurs utilisateurs accèdent au mêmes fichiers, en même temps, des problèmes de concurrence d’accès se posent : quelle modification sera retenue ? quelle valeur sera lue ?
Pour manipuler une base de données, on utilise donc généralement un logiciel spécialisé : un SGBD (Système de Gestion de Bases de Données)[^2].
Utilisation d’une base de données
La création d’une base de données s’effectue avec un objectif : elle doit permettre de retrouver de l’information par son contenu en se fondant sur des critères de recherche. Par exemple, en 1959, dans quels morceaux et quel(s) album(s) de Miles Davis apparaît John Coltrane ?
Pour réaliser l’indépendance annoncée dans la définition précédente, on associe à la base de données une description que l’on appelle métadonnée (ou catalogue). Cette description décrit la structure interne de la base de données[^3]. En plus de la structure et du type des données, on stocke également à cet endroit les informations concernant les règles de cohérence des données (cf. section suivante sur la qualité d’une base de données).
| NumCD | Titre | Interprète | Label | Année |
|---|---|---|---|---|
| 1 | Bring On the Night | Sting | 1986 | |
| 3 | Superstition | Stevie Wonder | Motown | 1972 |
| 2 | Paranoid Android | Radiohead | Parlophone | 1997 |
Extrait d’une base de données pour une collection de CD musicaux.
Dans l’exemple donné dans le Tableau 1., en plus des informations, la base de données contiendrait les métadonnées suivantes :
-
« NumCD » est un nombre entier supérieur à 1 ;
-
« Titre » est une chaîne de caractères de taille 50 ;
-
« Interprète » est une chaîne de caractères de taille 30 ;
-
« Label » est une chaîne de caractères de taille 20 ;
-
« Année » est un nombre entier supérieur à 1900 et inférieur à l’année en cours.
- Remarque
- On note que tous les « champs » ne sont pas forcément renseignés dans l’exemple donné.
Qualité d’une base de données
L’un des objectifs de création d’une base de données est de pouvoir retrouver les données par leur contenu. Il faut donc s’assurer que ces dernières sont de « bonne qualité ».
- Cohérence des données contenues dans la base
-
Par exemple, si un champ doit contenir la qualité d’une personne sous la forme « Monsieur », « Madame », « Mademoiselle », l’entrée de « M. » doit être impossible de façon à ne pas induire des erreurs de recherche sur ce Champ.
- Absence de redondance
-
Dans un carnet d’adresses le stockage du nom de la ville et du code postal pour chaque personne représente une redondance : la même information est stockée plusieurs fois, ce qui consomme de la place inutilement.
Le modèle relationnel des données s’accompagne d’outils qui permettent de détecter, dans une certaine mesure, les problèmes présentés dans cette section.
Modèles de données
Ces modèles reposent sur des recherches initiées à partir des années 1960. Parmi tous les modèles développés et utilisés, on ne présentera ici (très succinctement) que deux modèles : le modèle hiérarchique et le modèle relationnel.
Modèle hiérarchique
Ce modèle est l’un des plus anciens modèles. À l’époque de sa définition, le traitement de l’information était encore très lié à l’organisation des fichiers sur une machine. Les modèles conceptuels des données étaient donc des graphes ou des arbres.
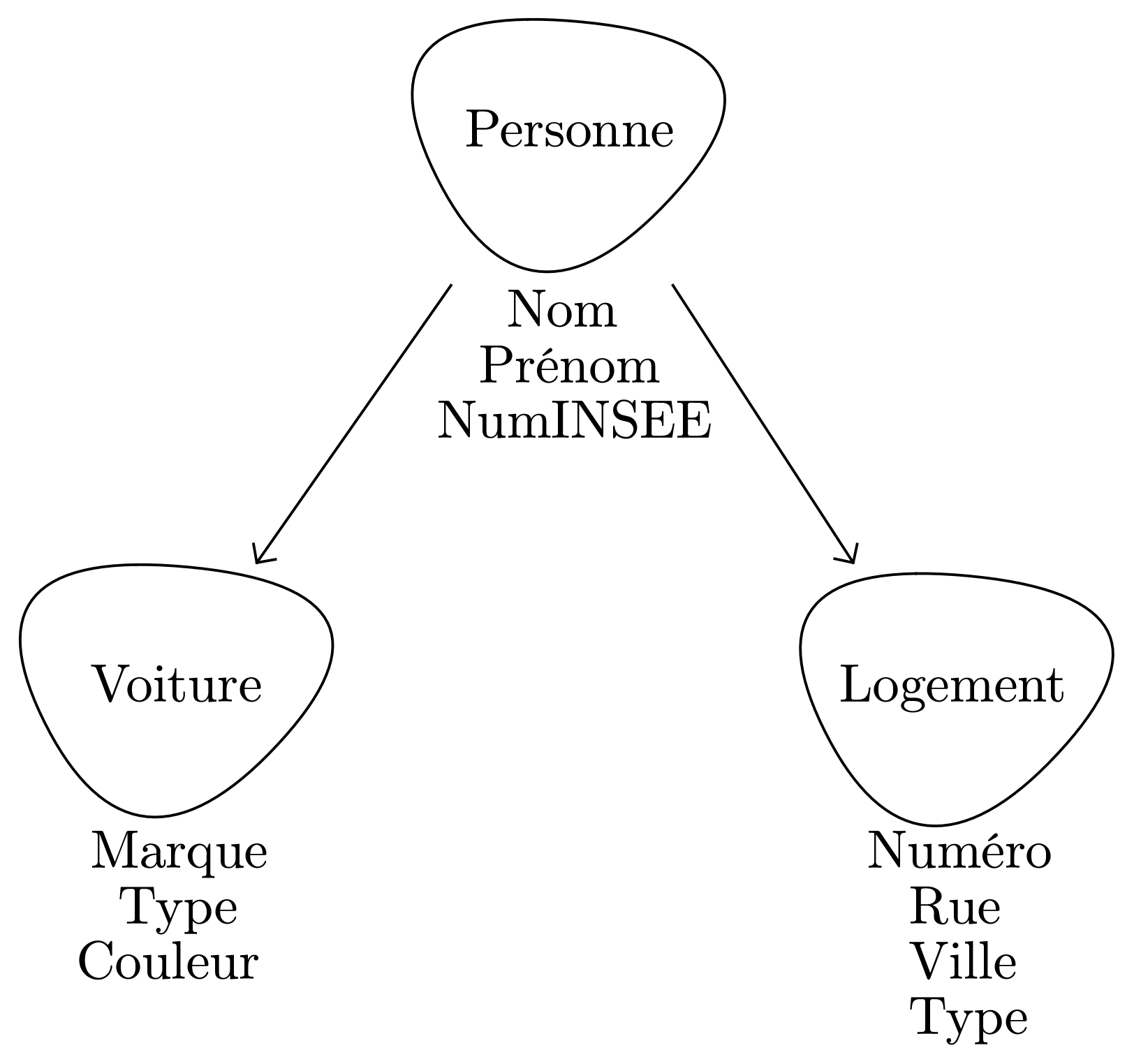
Le modèle « hiérarchique » propose donc une classification arborescente des données, à la manière d’une classification scientifique. Dans ce modèle, chaque enregistrement n’a qu’un seul possesseur, ce qui limite les modélisations de la réalité possibles.
Des SGBD de type « hiérarchique » ou « réseau » (extension du modèle précédent permettant des relations transversales) sont toujours utilisés, pour des raisons d’efficacité, lorsque la structure de données s’y prête.
Le système d’exploitation Windows utilise « une base de registre » pour stocker tous les paramètres de configuration (système et logiciels). Le modèle de données choisi est le modèle « hiérarchique ».
La donnée Favoris, par exemple, a pour chemin : HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Applets\Regedit\Favorite (on peut accéder à cette donnée grâce au logiciel Regedit).
Modèle relationnel
Ce modèle a été proposé en 1970 par E. F. Codd dans un article resté célèbre : « A Relational Model of Data for Large Shared Data Banks ». Il cherchait à créer un langage d’interrogation de bases de données plus proche du langage naturel. Dans cette optique, il a fondé sa recherche sur des concepts mathématiques rigoureux, tels que la théorie des ensembles et la logique du premier ordre.
Présentation du modèle relationnel
Qu’est-ce qu’une relation ?
On appelle relation unobjet de la vie réelleauquel on attache un ensemble d’attributs.
Par exemple, un employé possède un nom, un prénom, un matricule, travaille dans un service et a été embauché à une certaine date.
-
Chaque instance d’une relation est appelée un tuple ou n-uplet (en français).
-
Les relations sont d’ordinaire représentées sous la forme de tables à deux dimensions, et on confond les deux concepts. On confond de même ligne dans la table et tuple.
-
Par définition, chaque tuple d’une relation est unique, et est identifié par un attribut ou une combinaison de plusieurs attributs qui forme la clef primaire.
-
L’ordre des tuples dans la relation n’est pas significatif.
-
Le nombre de champs de la relation s’appelle le degré de la relation tandis que le nombre de tuples dans la relation s’appelle la cardinalité de la relation.
- Exemple
- Base de données formée par deux relations.
| Titre | Directeur | Acteur |
|---|---|---|
| Casablanca | M. Curtiz | Humphrey Bogart |
| Casablanca | M. Curtiz | Peter Lore |
| Les 400 coups | F. Truffaut | J.-P. Leaud |
| Star Wars | G. Lucas | Harrison Ford |
Relation
Film
| Titre | Salle | Heure |
|---|---|---|
| Casablanca | Lucernaire | 19:00 |
| Casablanca | Studio | 20:00 |
| Les 400 coups | Sel | 20:30 |
| Star Wars | Sel | 22:15 |
Relation
Séance
- Quelle est la cardinalité de la relation
Film?
Réponse
La cardinalité d’une relation est le nombre de tuples (ou de lignes) qu’elle renferme. Ici la cardinalité est égale à 4.
- Quel est le degré de la relation
Séance?
Réponse
Le degré d’une relation est le nombre de champs qui la définissent. Ici, c’est 3.
- Quels sont les attributs (champs) de la relation
Film?
Réponse
Les attributs de la relation Film sont : Titre, Directeur, Acteur.
- Indiquer un tuple de la relation
Séance.
Réponse
LA cardinatlité de la relation étant égale à 4, on a le choix entre 4 réponses. (Casablanca, Lucernaire, 19:00) fait partie de ces réponses possibles.
Qu’est-ce que le calcul relationnel ?
- Exemple
- Existe-t-il un film ayant pour acteur Humphrey Bogart diffusé au cinéma Studio ?
- Existe-t-il au moins un film de M. Curtiz projeté au cinéma Sel ?
- F. Truffaut a-t-il fait tourner l’acteur Harrison Ford ?
Qu’est-ce qu’une vue ?
Les relations constituant la base de données sont complétées à l’aide de vues :
Une vue est une relation, qui au lieu d’être stockée dans la base de données, est le résultat d’une requête.
Une vue peut ensuite être réutilisée exactement comme s’il s’agissait d’une relation stockée dans la base de données.
- Quelles sont les films, les salles et les horaires des séances dans lesquels on peut trouver l’acteur Humphrey Bogart ?
Réponse
La réponse à cette requête est une vue :
| Casablanca | Lucernaire | 19:00 |
| Casablanca | Studio | 20:00 |
Qu’est-ce que le langage SQL ?
Toujours dans le cadre de sa recherche, Codd a mis au point, en même temps que le modèle de données relationnel, un langage d’interrogation des données SEQUEL, qui est par la suite devenu SQL (Structured Query Language). La normalisation du langage SQL, dès 1986 par l’ANSI (institut de normalisation américain), puis par l’ISO (organisation internationale de la normalisation) a assuré, pour une grande partie, le
succès du modèle relationnel. Les requêtes écrites pour un SGBD fonctionnent en général sans trop de modifications avec un autre SGBD.
- Exemple
- Traduction en langage
SQLde l’interrogation de la question 5.
|
|
Systèmes de gestion de bases de données
Les SGBD sont des systèmes complexes qu’il n’est pas question de décrire en détail.
Rendre efficace la recherche d’une information dans un fichier informatique n’est pas simple
Comme on l’a déjà vu cette année, lorsqu’on utilise un fichier pour stocker de l’information, il est nécessaire de prévoir un découpage de celui-ci par enregistrements, souvent de taille fixe. Pour passer d’un enregistrement à l’autre, il faut alors avancer la « tête de lecture » de la taille d’un enregistrement.
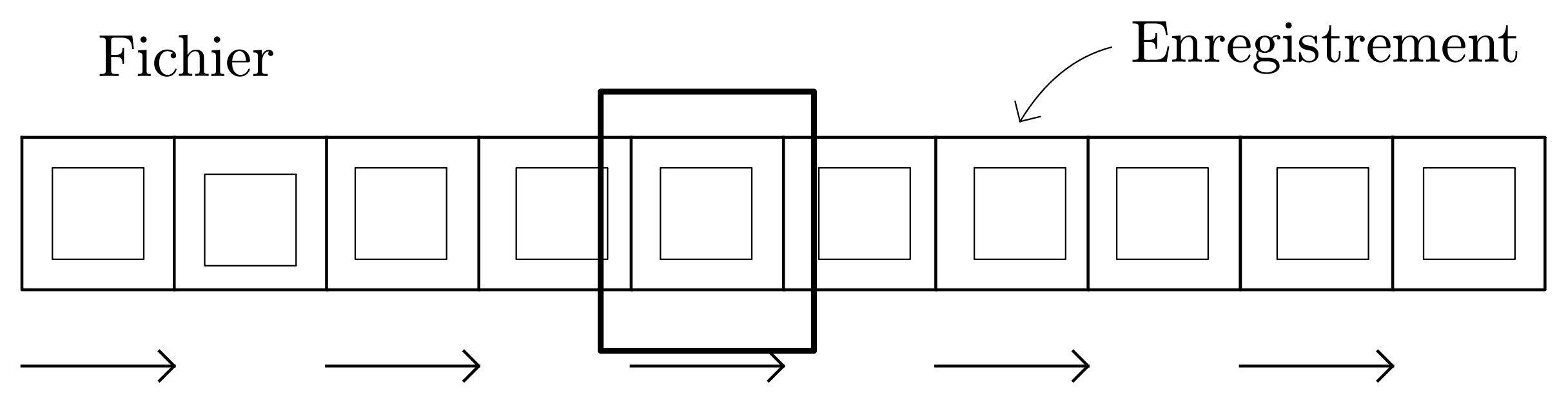
Dans une base de données, on recherche les données par leur contenu. Pour retrouver l’une d’entre elles, il faut donc parcourir tous les enregistrements un à un (recherche séquentielle) et en examiner le contenu, ce qui est relativement peu efficace.
Une alternative à ce parcours séquentiel est la construction de tables descriptives afin d’accélérer l’accès aux données :
-
Une première table permet l’accès direct à un enregistrement par une « clé » associée à l’adresse mémoire de l’enregistrement.
-
Une seconde table contient l’ordre relatif des enregistrements ordonnés suivant les valeurs d’un champ : on appelle cette table un index. Cette seconde table permet d’employer des méthodes de recherche par le contenu du champ indexé beaucoup plus performantes. La recherche dichotomique est l’une d’entre elles.
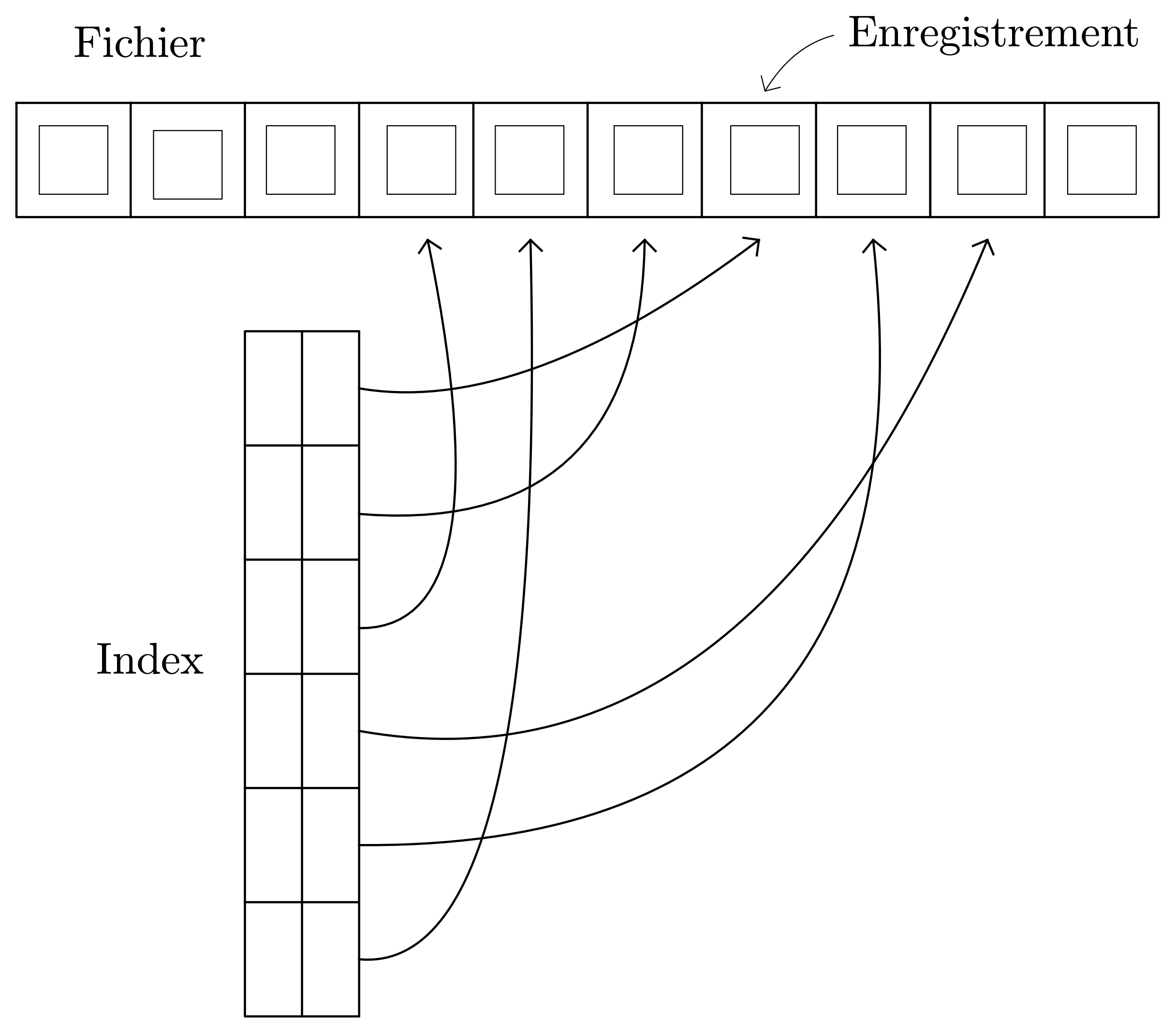
On voit, à travers ce simple exemple de recherche du contenu d’un enregistrement, qu’un SGBD doit implémenter des algorithmes sophistiqués.
Fonctionnalités d’un SGBD
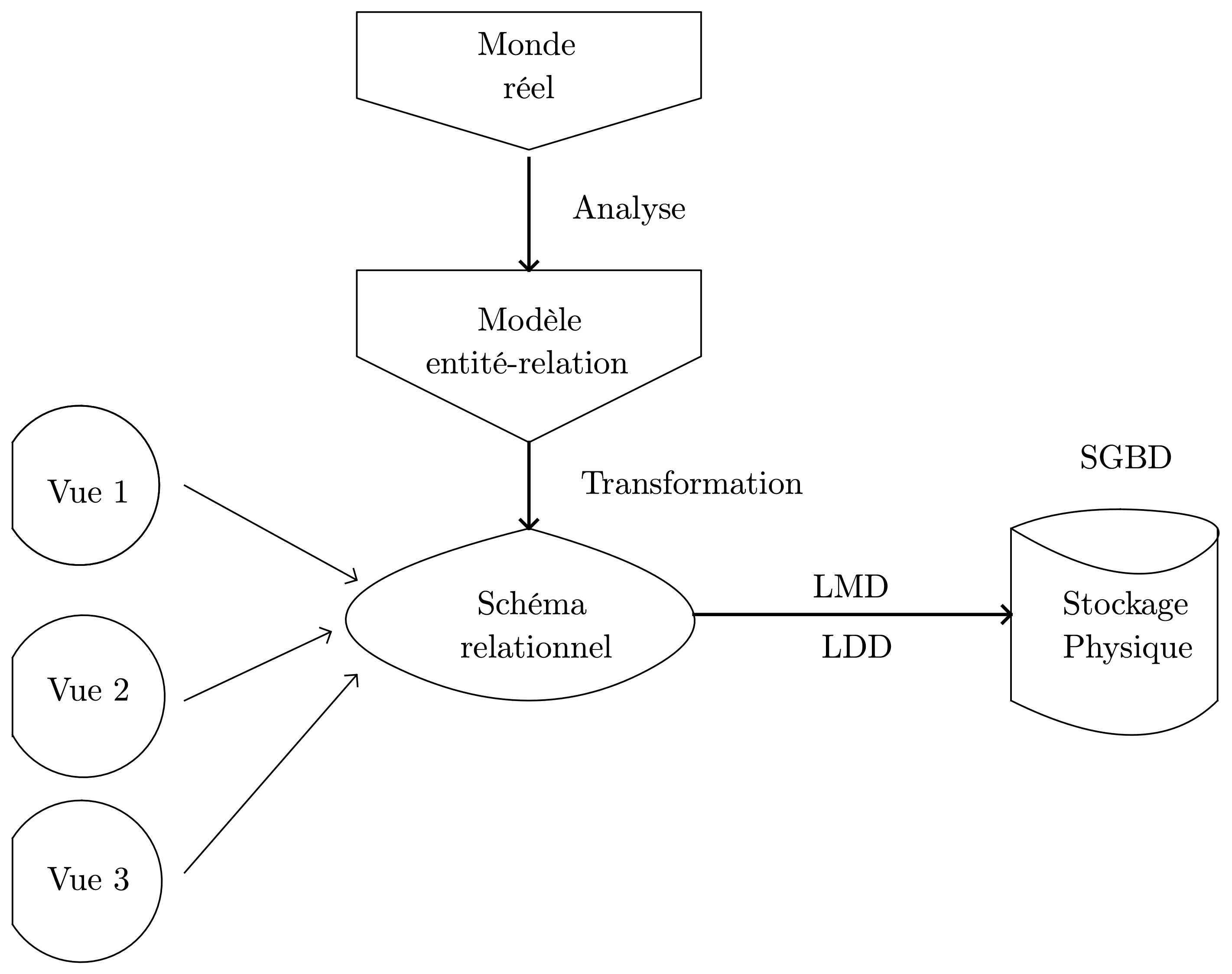
Pour concevoir et organiser les fonctionnalités d’un SGBD on peut s’appuyer sur un modèle en trois-couches dont l’objectif est d’obtenir, une indépendance entre les données et les traitements :
- Niveau interne ou physique
-
C’est le niveau le plus proche du matériel. À ce niveau, on gère :
-
le stockage dans les fichiers des données, du schéma, des index, ... ;
-
le partage des données et la gestion de la concurrence d’accès ;
-
la reprise sur panne (fiabilité) ;
-
la distribution des données et l’interopérabilité (accès aux réseaux).
-
- Niveau conceptuel ou logique
-
À ce niveau, on :
-
définit la structure des données : Langage de Description des Données (LDD) ;
-
définit comment les données peuvent être consultées et mises à jour : Langage de Requêtes (LR) et Langage de Manipulation des Données (LMD) ;
-
gère la confidentialité (sécurité, droits d’accès aux données à travers le réseau, ...) ;
-
maintient l’intégrité des données.
-
- Niveau externe
-
Le niveau externe sert à décrire les « vues » des utilisateurs, c’est à dire le schéma de visualisation des données, qui est différent pour chaque catégorie d’utilisateur. C’est à ce niveau qu’on retrouve le langage SQL.
Ce découpage permet de modifier un sous-niveau sans toucher aux deux autres.
Transactions
Les transactions doivent posséder les propriétés suivantes :
- Atomicité
-
Une transaction est effectuée en totalité ou abandonnée.
- Cohérence
-
Une transaction doit s’effectuer d’un état cohérent de la base vers un autre état cohérent.
- Isolement
-
Des transactions différentes ne doivent pas interférer.
- Durabilité
-
La transaction a des effets permanents, même en cas de panne.
Architectures
- Architecture à deux niveaux Client/Serveur
-
L’architecture à deux niveaux, appelée architecture 2-tiers (tier signifie niveau, étage en anglais), caractérise les systèmes Clients/Serveurs dans lesquels le client demande une ressource que le serveur fournit directement.
La relation est donc directe entre le serveur et le client.
- Architecture à trois niveaux
-
Dans l’architecture à 3 niveaux, appelée architecture 3-tiers, il existe un niveau intermédiaire, c’est-à-dire que l’on a généralement une architecture partagée entre :
-
Le client, qui demande les ressources ;
-
Le serveur d’application (Middleware), qui reçoit les demandes, interroge le serveur et retourne les réponses (après avoir éventuellement effectué un traitement) ;
-
Le serveur secondaire (généralement le SGBD), qui répond aux requêtes du serveur d’application.
-
Dans l’architecture à 3 niveaux, chaque serveur (niveaux 1 et 2) ffectue une tâche (un service) spécialisée. Ainsi, un serveur peut utiliser les services d’un ou plusieurs autres serveurs afin de fournir son propre service. Par conséquent, l’architecture à trois niveaux est potentiellement une architecture à $N$ niveaux.
Comparaison des deux types d’architectures
L’architecture à deux niveaux est donc une architecture Client/Serveur dans laquelle le serveur est polyvalent, c’est-à-dire qu’il est capable de fournir directement l’ensemble des ressources demandées par le client.
Dans l’architecture à trois niveaux par contre, les applications au niveau serveur sont délocalisées, c’est-à-dire que chaque serveur est spécialisé dans une tâche (serveur web et serveur de base de données par exemple).
Ainsi, l’architecture à trois niveaux permet :
-
une plus grande flexibilité/souplesse ;
-
une plus grande sécurité (la sécurité peut être définie au niveau de chaque service) ;
-
de meilleures performances (les tâches sont partagées).
Étapes de la conception de bases de données
On peut décomposer le processus de conception d’une base de données en plusieurs étapes :
-
Analyse du système du monde réel à modéliser ;
-
Mise en forme du modèle pour l’intégrer dans le SGBD ;
-
Création effective dans le SGBD des structures et leur remplissage.